

Data Center Flexibility: Implementation and Deployment Pathways
Chapter 5


The previous chapters showed that data center flexibility is both technically feasible and economically compelling. The challenge now is scale. This chapter outlines how industry can move from today’s pilots to a 2030s system. One that meets data center growth, avoids negative cost impacts, maintains resource adequacy, and supports decarbonization. Flexibility remains the key lever, but it must be integrated with and bridge to clean-firm supply options. In addition, it must also be supported by market and regulatory structures that reward verified performance.
Section 5.1 evaluates technology and market readiness. It outlines which flexibility tools are deployable today, which are emerging and need clearer rules to scale, and which remain in development. Together, these pathways show how compute, storage, cooling, and controllable load can work together with clean-firm generation. These, in turn, can deliver reliable capacity for digital infrastructure at the lowest total system cost.
Section 5.2 turns into participation models and the market structures, determining how flexibility participates in wholesale and retail programs.
Section 5.3 highlights main supporting mechanisms, including commercial, planning, and regulatory services, enabling market participation, so that data center flexibility can scale from pilots to full portfolio deployment.
5.1 Technology readiness level and market adoption
Moving from pilots to first-(FOAK) and second-of-a-kind (SOAK), then eventually Nth-of-a-kind (NOAK) projects to system-scale flexibility will not happen on its own. It requires coordinated progress across technology, market design, and regulatory frameworks, and it has to happen on a clock. To make that path concrete, we use a three-phase technology readiness framework that reflects where the ecosystem is today and where it is heading:
Ready to deploy (next 18 months): technologies and models that work now and can scale within 18 months.
Emerging (2027–2028): capabilities are technically proven but still need to address hurdles from technology advancements, regulations, and financing structures.
Development pipeline (2029–2030): the next wave, systems that will define how digital load and clean energy co-deploy at scale.
To guide implementation, impactECI rates each flexibility option across three criteria: technology readiness, site availability and market adoption for grid services, each on a 1–9 scale.
Technology readiness level (TRL) assesses how mature the underlying solution is. It ranges from early-stage concepts and pilots (1-4), to FOAK and scaling deployments (5-7), to proven/widely deployable technologies (8-9).
Site availability captures how widely the tools are installed or available on-site, ranging from rare or pilot-only presence (1–3), growing and moderate presence across sites (4–6), to common to nearly universal deployment almost every site (7–9).
Market adoption captures the deployment rate and popularity in data centers and utility programs, where lower scores indicate emerging offerings and higher scores reflect established products, contracts, and business models. These rankings not only highlight what can work, but what operators and policymakers can count on within the next 18 months to the 2030s.
5.1.1 Ready to deploy (the next 18 months)
The ready-to-deploy solutions highlight tools that already work at scale inside data centers. They can also be expanded quickly with the right contracts and standards. Temporary workload shifting, site-level DR and interruptible services, backup generation, BTM BESS, thermal energy storage (TES) and grid-interactive UPS+BESS are all technically mature, with TRLs of 7–9 and rising market adoption.
Dynamic line ratings (DLRs) also fall into this near-term category as a transmission-side enabler that can be deployed today. DLRs can materially increase real time capability and headroom for flexible load. The technology is well-validated (TRL 8-9), but adoption by utilities and grid operators remains limited (roughly 4-6 range). Scaling up will require full implementation of Federal Energy Regulatory Commission‘s order 881 and its follow‑on ANOPR, common operating standards across ISOs/RTOs, cost recovery, and integration of real-time ratings into market operations and interconnection studies.
The immediate priorities are to standardize telemetry and establish a baseline for compute and on-site assets. There needs to be a rollout for template tariffs and interconnection agreements for large flexible loads. Finally, there needs to be updates to the runtime and emissions rules so that existing backup and storage systems can safely support short-duration capacity, reserves, and flexible interconnection.
The goal through 2026 is to set these capabilities as standard designs of new and retrofit campuses, so every additional MW/GW of digital load installed has flexible capacity.
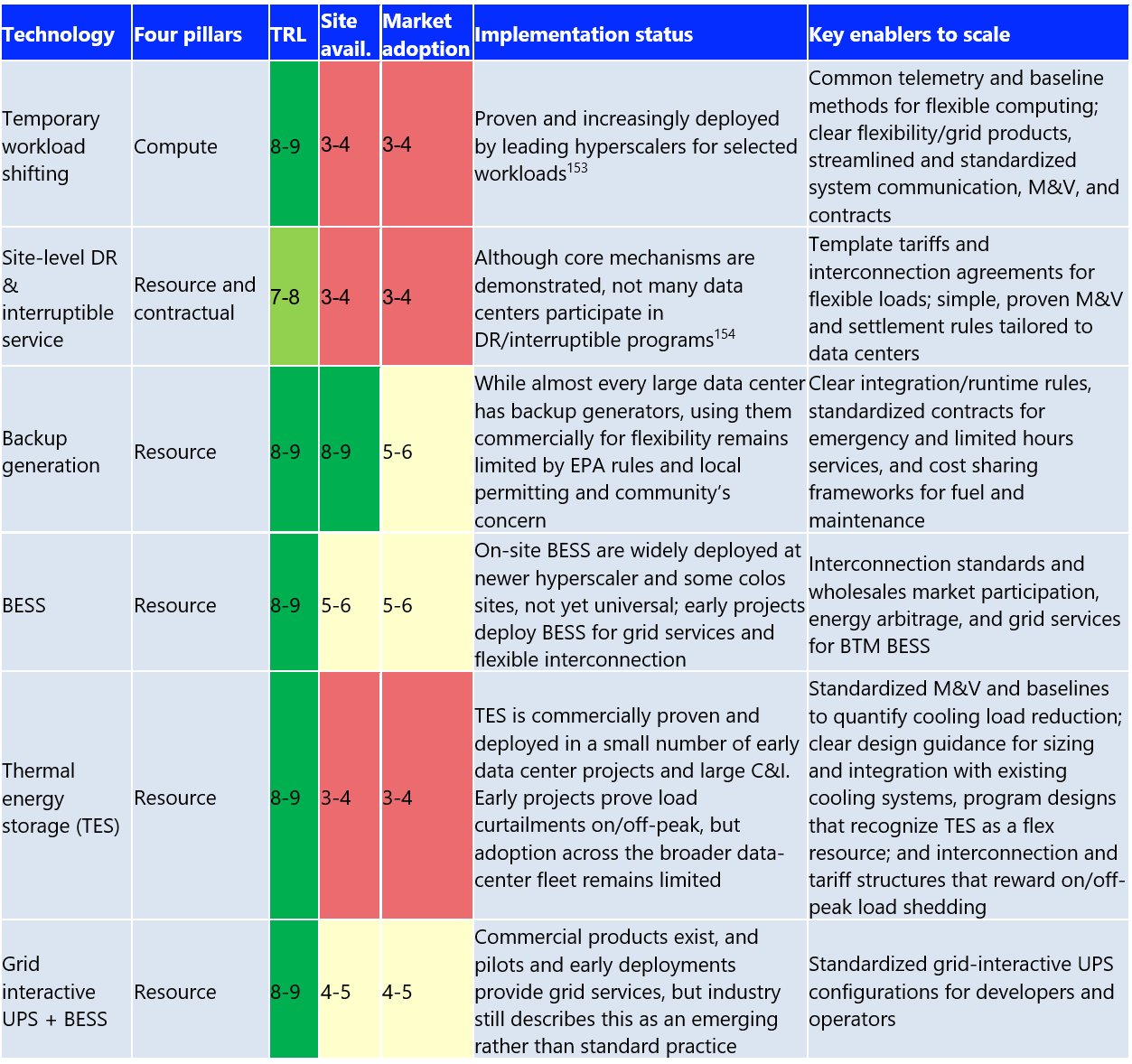
Source 153 and 154: https://blogs.nvidia.com/blog/ai-factories-flexible-power-use/ and https://www.publicpower.org/periodical/article/google-tva-enter-agreement-tied-data-center-demand-response
5.1.2 Emerging (2027-2028)
The emerging solutions cover technologies and resources that are technically proven but not yet widely used, especially for grid services and flexibility. Advanced cooling and facility optimization, spatial workload shifting across regions, multi-site grid-aligned orchestration, and data-center-centric DR aggregations now sit in the 6–8 TRL range. Yet each faces regulatory gaps, unclear market rules, and lack of common standards and interfaces. The task through 2027–2028 is to turn these pilots into standardized offerings that both operators and utilities can rely on. That includes reliability-safe, AI/ML-driven cooling controls across a wide range of sites and deploying SLA-aware orchestration platforms that coordinate assets across multiple sites. In addition, data-center-centric products can be built with consistent telemetry, measurement and verification, and performance guarantees designed to fit data center operations.
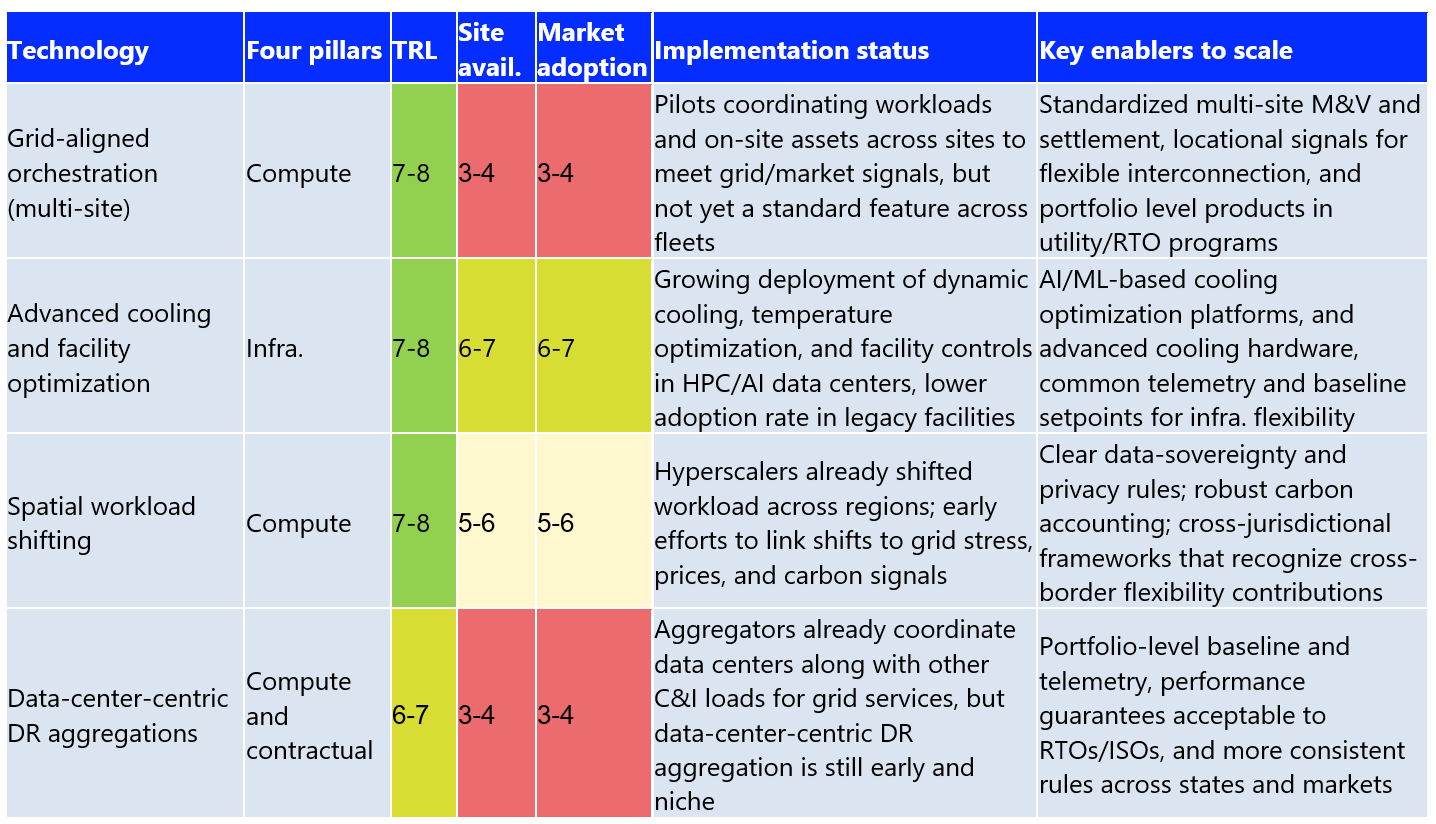
Why do we need data-center-centric-aggregation models beyond traditional DR?
Traditional C&I demand response aggregations are well-established, and aggregators already manage large portfolios across multiple markets. Hyperscale-specific aggregations, where multiple large data centers provide coordinated, verifiable flexibility, are still in early deployment, but grid operators are actively testing these models.
Utilities or aggregators call a handful of multi-hour events each year. In most cases, residential and C&I facilities respond by adjusting HVAC setpoints-smart thermostats, trimming non-essential loads (like lighting)-behavior load shaping, or switching backup power (gas/diesel gensets, battery, EVs, or rooftop solar)-Figure 30.
That model may work for those facilities, but it doesn’t align well with data center operations. For instance, aspects like uptime requirements, multi-tenant SLAs, and tightly engineered N+1 and N+2 power and cooling architectures make curtailments difficult.
Data centers can provide flexibility, but it’s granular and tied to specific workloads and on-site assets. The load reductions come from orchestrating compute, storage, cooling, batteries, and generators, with adjustments over seconds to minutes.
Unlocking this potential requires data-center-centric aggregation models that treat these systems as a controllable portfolio, not a single switch flipped a few times a year. Aggregators like Voltus, Enel X, and CPower Energy are already moving in this direction. They are building dedicated data center portfolios, supported by forecasting, dispatching, and portfolio-management platforms. Other companies, such as Honeywell, Siemens, ABB, and Schneider Electric, are adapting their automation and microgrid platforms for multi-site data center operations.
Together, these shifts mark the emergence of a new flexibility model, one built around precision, orchestration, and continuous performance, not manual responses to a handful of DR calls.
5.1.3 Development pipeline (2029-2030)
The development pipeline is where the next generation of options is starting to take shape. These are the technologies that could truly change how low-carbon, flexible data-center campuses are powered and optimized. Most of them are still either in early FOAK deployments or in R&D, including BTM hydrogen fuel cells, co-location geothermal, SMRs and quantum technology.
Now, these solutions sit in the middle or early end of the TRL range (roughly 2–7), with very limited commercial adoption (1-3). What we’re seeing in the market are pilots, design studies, licensing work, and only the first wave of commercial offers.
Looking ahead to 2030, the priority is clear. There needs to be a way to prove bankable business models through pilots to FOAK and SOAK projects, set clearer rules for valuing clean-firm capacity, streamline licensing pathways, risk-sharing mechanism, supply security and financing options. If done right, these technologies could anchor clusters of grid-interactive, always-available, and increasingly autonomous data-center campuses by the early 2030s.
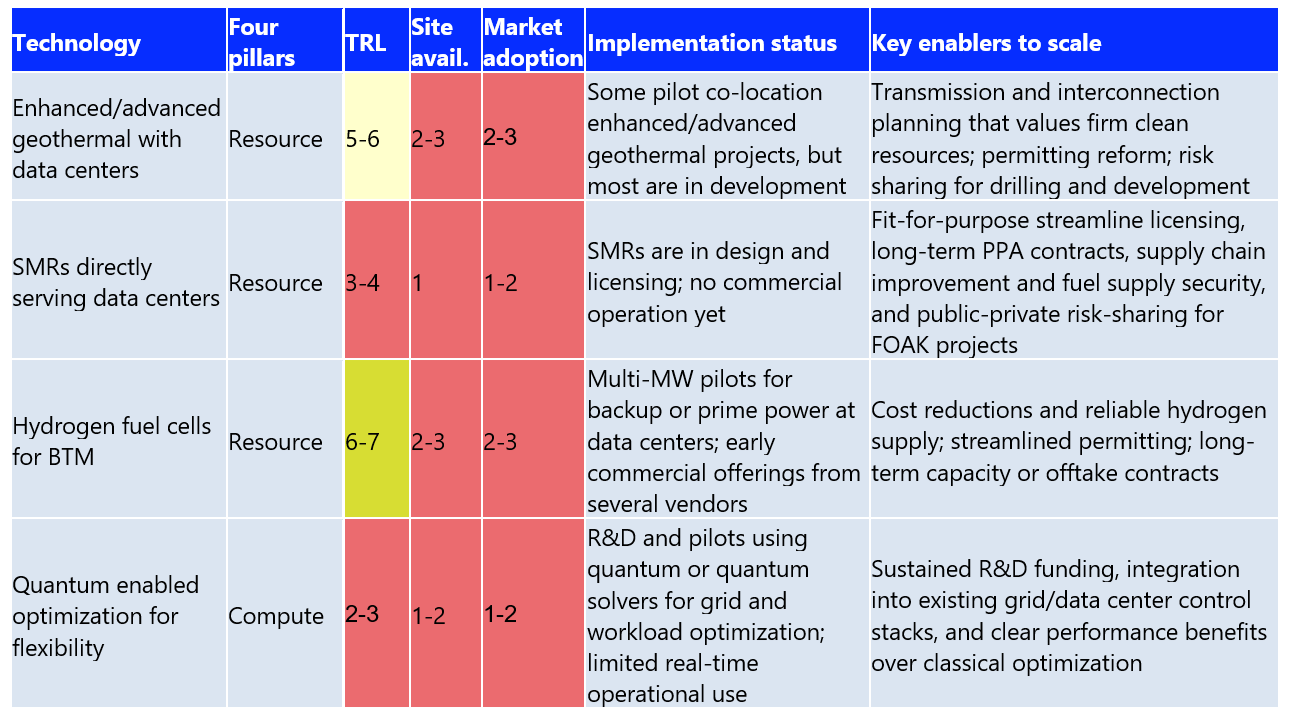
a) How SMRs, geothermal, and hydrogen can anchor flexible campuses
By the late 2020s, early deployments of zero-carbon firm power at or near data center campuses are likely to move from pilots to commercial projects. These resources complement demand-side flexibility by providing always-on or load-following/dispatchable clean power closely matched to digital load growth. It is important to map these technologies to understand the options in an optimal future state.
Small modular reactors (SMRs): SMRs are attracting interest as potential clean baseload or load-following power for large campuses. Projects are still in the design and licensing stages, but there aren’t any operational co-location SMR-data centers yet in service. Progress will hinge on licensing reform, FOAK challenges, construction cost overruns, and long-term contracts that align nuclear economics with data center timelines.
Enhanced and advanced geothermal: Next-generation geothermal developers are targeting firm power supply for large loads and data center colocation. While total deployment remains modest, early projects show how geothermal can anchor flexible, grid-interactive data centers. A few pilots are already underway, for example, Fervo Energy 115 MW deal with Google, and Mazama Energy‘s super-hot-rock pilot in Oregon.
Hydrogen fuel cells: Multi-MW hydrogen systems were installed as pilots for backup power. These included Microsoft‘s multi‑MW projects with Caterpillar Inc./Ballard Power Systems in Wyoming and a 3 MW system developed with Plug Power. Both systems were designed to replicate conventional diesel backup performance at full data center scale.
In the near term, most projects would rely on grey and blue H2 until green H2 becomes cost competitive. Most grey and blue H2 (with CCUS) today is produced from natural gas as feedstock via steam methane reforming or related reforming routes (ATR). While fuel cells offer much lower NOx and other emissions than gas or diesel gensets, their lifecycle CO₂ impacts vary significantly. Grey H2 can have higher lifecycle emissions/MWh than modern CCGT, and some blue H2 pathway delivers only 15-18% GHG reduction compared to grey or even comparable CCGT depending on capture rates and methane leakage. Hence, using grey and blue H2 is costly and less energy efficient than burning natural gas directly. Scaling green H2 fuel cells for data center will therefore depend on supply chains, learning curve cost declines, and regulatory signals that favor low-carbon H2.
b) What is the future of compute flex and system optimization-quantum computing technology?
Quantum optimizations are emerging as promising tools for complex grid and energy problems. This includes power-flow optimization, storage scheduling, and contingency management. In addition, early studies of quantum optimizations are emerging as promising tools for complex grid and energy problems in controlled settings. Despite this, consistent real-world quantum applications have not yet been demonstrated.
For hyperscalers, this signals a future in which quantum-classical platforms help co-optimize workload routing and energy use across cost, carbon, and reliability objectives. Quantum Long Short-Term Memory (LSTM) models have already outperformed classical LSTMs in solar-forecasting benchmarks, pointing to potential roles in predicting renewable output and grid stress, so flexibility becomes more planned and less reactive.
Several pilots and studies show how this could eventually tie into data center flexibility. IBM and E.ON are testing hybrid quantum-classical optimization for grid operations. While still pre-commercial, the effort highlights how quantum optimization could eventually support more autonomous, real-time coordination of flexible loads, storage, and grid operations. NREL has linked quantum computers to real grid hardware in the loop to explore quantum-based control for balancing and flexibility services. There is ongoing research on quantum-assisted grid optimization. In them, they are evaluating congestion relief, storage dispatch, EV coordination, and flexible-load orchestration that mirrors multi-asset coordination for grid-interactive data center campuses.
Case Study 1: IBM and E.ON explore quantum-enabled grid optimization
Challenge: There are many complexities in energy trading and distribution, especially as grid demands rise. A mix of changing weather, supply shifts, and evolving consumption patterns stretches classical computing methods. E.ON still needs to plan ahead and serve customers at fixed prices.
Solution: E.ON and IBM partnered to explore quantum computing as a tool for tackling these energy pricing challenges. Together, they built a quantum algorithm that incorporates weather risk and estimates the cost of offering energy at given prices over the life of a contract. They are also using IBM’s Qiskit to break down the problem into manageable pieces.
Results and impacts: IBM has demonstrated that its quantum hardware and software can carry out these kinds of calculations at a strong scale. E.ON’s work with these tools is laying the groundwork for greater efficiency, and ultimately, better prices for customers.
Case Study 2: NREL-Atom Computing quantum-in-the-loop demonstration
Challenge: As EVs, DERs, sensors, and flexible loads ramp up, grid operators face optimization problems that are too large/complex for today’s classical solvers. Until recently, researchers had no practical way to evaluate whether quantum computing could help.
Solution: National Renewable Energy Laboratory, Atom Computing, and RTDS Technologies Inc. developed an open-source, vendor-neutral interface that connects quantum processors directly to real-time grid simulators on NREL’s ARIES platform. A custom API enables two-way, real time data exchange between quantum and classical solvers. The API ensures that tasks are translated into quantum-ready formulations, such as QUBO, and variational circuits (QAOA, VQE). This setup allows quantum algorithms to respond dynamically to changing grid conditions for applications including EV-charging coordination, optimal power flow, and contingency analysis.
Results and impacts: Early experiments have shown that quantum algorithms can solve small grid-optimization problems. The solution quality is comparable to classical approaches, establishing a baseline for tracking future quantum advantage. The new interface gives utilities, engineers, and aggregators a realistic simulation for assessing quantum methods under live grid conditions. While quantum advantage hasn’t been demonstrated yet, the project eliminates a major barrier by enabling quantum algorithms to be validated in real-time power-system simulations. This is instead of the static, offline models.
Industry leaders like IBM, Google, AWS, and Microsoft are testing quantum-based optimization through their cloud platforms. Early pilots that combine quantum algorithms with reinforcement learning in buildings and campus-scale energy systems show meaningful reductions in modeled or pilot-scale energy use and emissions. They offer a preview of how similar methods could eventually be applied to data center portfolios. Progress toward quantum technology depends on scaling quantum hardware and system integration between existing control and orchestration. Both are making progress, but it’s still early. If the problems are solved, quantum-enabled optimization could support more autonomous, real-time coordination of workloads. They may also support energy use that better tracks grid needs. This makes intelligent flexibility a core feature of digital infrastructure rather than an add-on.
5.2 Market mechanism innovation
The shift from pilots to scalable data center flexibility requires market structures that make participation practical, profitable, and low risk. This is driving the need for data-center-centric aggregators and new market models that treat data centers as dispatchable digital resources rather than passive loads.
Four primary models are shaping this next phase: Flexibility-as-a-Service (FaaS), VPPs and Bring-Your-Own-Capacity/VPP (BYOC/BYO-VPP) frameworks, direct market participation, and flexibility-contingent interconnection. These mechanisms lower barriers, align incentives, and create a pathway for operators to join wholesale and retail flexibility markets.
5.2.1 Flexibility-as-a-Service Models (FaaS)
Flexibility-as-a-Service turns flexibility from a one-off engineering project into a packaged service. Rather than managing their own grid participation, data centers could let aggregator platforms take care of dispatch, verification, and compliance.
As highlighted above, third-party aggregators, such as Enel X, Voltus, and Leap, are building portfolios of flexible data centers that collectively participate in wholesale markets. According to Wood Mackenzie, VPP capacity in North America grew +13.7% from 33 GW in 2024 to reach 37.5 GW in 2025. In addition, the number of participating companies, offtakers, and monetized programs increased by +33%. These platforms provide participants with performance guarantees, insurance products, and automated compliance tools.
However, beyond the unique challenges of data center operations, scaling FaaS for data centers still faces the same barriers that have constrained traditional DR/VPP. These include a lack of precedent, fragmented market rules, uneven qualification standards, heavy metering and communications requirements, and limited transparency in performance and incentives during grid events. Compensation often does not reflect the full reliability value that flexible, fast-responding loads can provide.
To enhance the data center portfolio, several gaps must be closed. Markets need more standardized DR and flexibility products, better measurement and verification methods tailored to digital loads, streamlined telemetry and data-sharing rules, and clearer financial signals tied to verified performance. Without these changes, FaaS will remain an option rather than a scalable tool for the broader data center fleets.
5.2.2 VPP and Bring-Your-Own-VPP (BYO-VPP)
VPPs and “Bring Your Own Capacity/VPP”- (BYOC or BYO-VPP) models are emerging as practical tools that let large loads (data centers) sponsor flexible capacity and convert it into faster, lower-risk interconnection. VPPs are fast, modular, and relatively low cost. Instead of waiting years for new gas speakers, long-lead transmission, or major distribution upgrades, a data center can fund a VPP that unlocks flexibility in homes and C&I businesses and treat that capacity as part of its own interconnection stack.
This concept is shaping policy. Amazon, Calpine, Constellation, Google, Microsoft, and Talen Energy have jointly proposed BYO-VPP structures within PJM Interconnection‘s “Joint Stakeholder Options PJM CIFP – Large Load Additions”. Their proposal outlined a new framework that allows operators to demonstrate verified flexibility via their own assets or third-party aggregators. In return, they earn expedited interconnection and reliability credits. The model is already gaining traction due to reductions in interconnection delays, lowered system costs, and preserving customer choice.

As brought up previously in part 3: “The six-tier ecosystem coordination model”, impactECI has outlined a simplified signal flow for data centers leveraging third-party aggregators. RMI also categorizes three commercial structures for large-load–powered VPPs, as below:
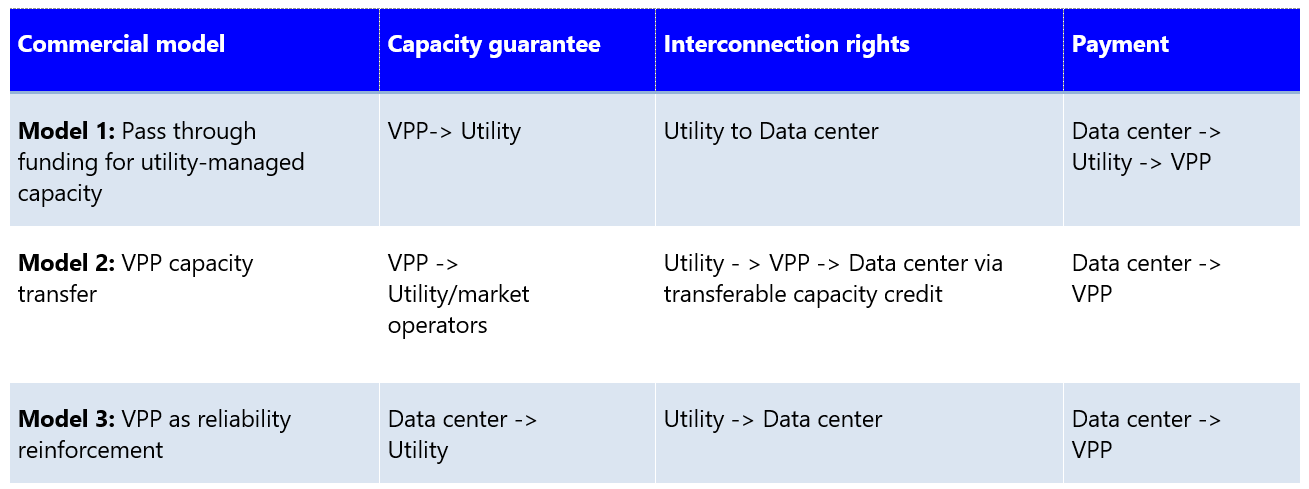
Model 1: Pass-through funding for utility-managed VPPs
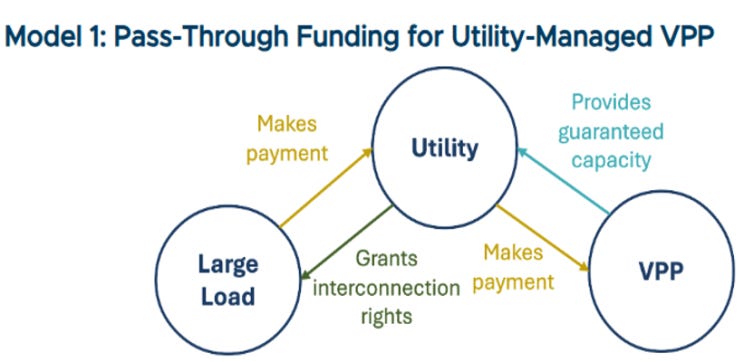
Data centers fund a utility-operated VPP portfolio, similar to a sleeved-PPA or green tariff. The VPP provides guaranteed capacity for the utility. While the utility grants expedited interconnection to the data center, it passes down program costs and benefits. The utility retains control of program design and performance management.
Model 1 offers data centers three advantages: they do not need deep VPP or grid-operations expertise, they receive a similar tariff product, and the utility remains visibly accountable for reliability. For utilities and regulators, the model aligns well with vertically integrated structures and can be slotted into existing clean-energy tariffs or DSM frameworks. Utilities, however, cover more risk if a large load delays or cancels its project. Utilities can mitigate that risk through upfront payment, guarantee cost recovery, or long-term contracts. Over time, Model 1 can mature into standardized “VPP-backed large-load tariffs,” similar to green tariffs in standardized corporate procurement.
Model 2: VPP capacity transfer
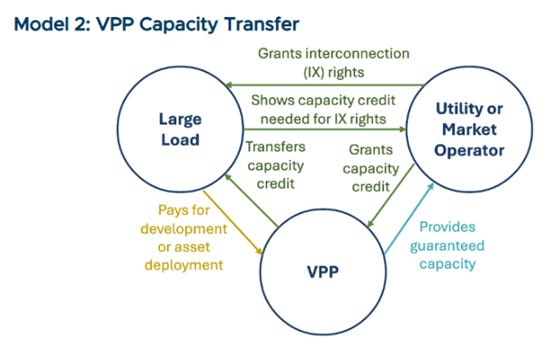
Model 2 shifts more control and commercial responsibility to the data center and the VPP aggregator, with the utility or market operator serving as the certifier of accredited capacity. The data center directly funds a third-party VPP developer, which aggregates DERs and secures capacity. The VPP then sells that capacity to the utility or clears it in the wholesale market, receiving an accredited capacity certificate or equivalent proof of contribution. That verified capacity is then “transferred” back to the data center in the form of accelerated interconnection or reduced capacity-related charges, based on an agreed exchange rate.
Model 2 works best in organized markets where capacity accreditation, testing rules, and transactions are already defined. It gives data centers flexibility to select among VPP developers, target portfolios in specific constrained zones, and negotiate commercial terms. Utilities can treat the VPP like any other supply-side capacity resource while still linking that capacity to a specific data center interconnection. The trade-off is increased complexity: the VPP, utility, and data center must coordinate on delivery and performance risk (penalties, hedges, LDs), and accreditation rules that make the transferred capacity credible. When aligned, model 2 creates a true “bring your own stack” option in which data-center-sponsored VPPs sit alongside utility-scale resources in the planning stack and earn equivalent recognition for enabling faster interconnection.
Voltus’s Bring Your Own Capacity (BYOC) is an early commercial version of model 2, tailored to data centers. Hyperscalers or developers pay Voltus to build a VPP in the same constrained region where they need interconnection. Voltus aggregates DERs into accredited capacity and contracts that capacity to the local utility. The utility then counts the VPP toward its planning needs and treats it as part of the capacity additions that accelerate interconnection for new data centers.
Model 3: VPP as reliability reinforcement
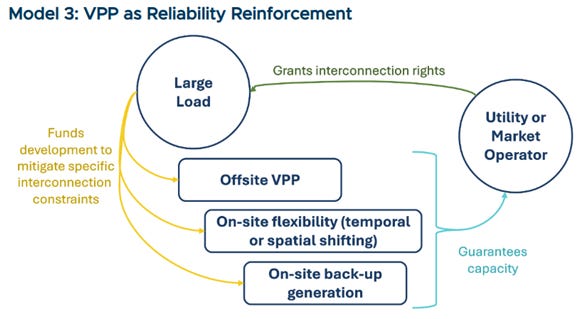
Data centers sign up for contractual flexibility with utilities/operators and then procure a VPP to help meet that commitment. The data center commits load reduction to the utility during specified windows. In addition, the VPP provides off-site flexibility resources to reduce loads. In this model, the VPP acts as an outsourced vendor, backed by strong measurement and verification, so that remote flexibility counts toward the data center’s contractual commitments.
In this model, the VPP contracts directly with the data center and is dispatched in coordination with utility signals and site-level controls, fulfilling the contractual flexibility agreement. The VPP provides verifiable off-site load reductions that count toward the data center’s obligations, supported by strong measurement, verification, and baseline methods. Model 3 works well in regions with existing interruptible service frameworks. This model gives data centers control over their reliability, provides utilities a single accountable load, and positions VPP aggregators as a third-party vendor delivering a reliability “service” for large load.
5.2.3 Direct market participation
Mature operators, particularly hyperscalers with dedicated energy teams, are beginning to participate in ISO/RTO markets (PJM, ERCOT, and California ISO). These data centers bid flexibility just like generation resources, providing demand response, capacity, ancillary, and frequency regulation.
Direct participation provides the biggest returns but requires investment in sophisticated control systems and real-time telemetry. Many operators use AI tools to optimize dispatch and to participate across multiple markets at once. They must also manage revenue streams from energy, capacity, and ancillary services while maintaining uptime.
For data centers with large portfolios, this provides full visibility and control over how flexibility is monetized. This positions operators to play a dual role. One where they are major consumers of electricity, and another where they are valuable partners in maintaining grid reliability.
Leading hyperscalers are already moving in this direction. They are treating flexibility as a portfolio asset rather than a site-level experiment. Google, for example, runs data-center DR programs via compute flex during grid events across the US, Europe, and Taiwan. Google and Northern Wasco County People’s Utility District successfully demonstrated day-ahead DR capabilities at Google’s facilities in The Dalles, Oregon. The company has also signed DR agreements with Indiana Michigan Power and Tennessee Valley Authority for new AI-focused facilities as a flexible grid resource. Microsoft is pursuing similar strategies. In several facilities, it has partnered with Eaton to use grid-interactive UPS systems. They can respond to grid conditions and provide frequency and voltage support. At its San Jose data center, Microsoft also operates an Enchanted Rock RNG-fueled microgrid that can dispatch during outages. This provides capacity and reliability services, generating revenues while maintaining uptime.
5.2.4 Flexibility-contingent interconnection
As introduced in section 2.4.2, flexibility-contingent interconnection is an emerging “speed to power” pathway that links faster and lower-cost grid access with a commitment to verifiable flexibility. Rather than waiting years for traditional transmission upgrades, data centers can secure conditional interconnection. The commercial logic is straightforward: flexibility unlocks access. Facilities can connect years earlier, and utilities can avoid costly, under-utilized infrastructure expansions.
Flexibility can take several forms. A site may drop a set amount of load when the grid is stressed, shift non-critical compute or cooling to off-peak windows via thermal energy storage, or offset demand using on-site batteries, generators, or contracted off-site VPP resources. Together, these options give operators different ways to meet their obligations without risking uptime.
Over time, this model will blend with VPP and “BYO-VPP” mentioned in section 5.2.2 above. Data centers won’t just flex their own load, they’ll bring portfolios of off-site storage, DERs, and aggregator managed capacity to meet interconnection obligations. In that sense, flexibility-contingent interconnection becomes the contractual shell, and VPPs and on-site assets become the tools that make those promises real at scale.
5.3 Supporting mechanisms
Across each model, a set of supporting commercial, policy, and operational services is emerging to strengthen the business case for participation and reduce risk for both utilities, aggregators, and data center operators.
Policy and planning enablers
Policy and planning structures are beginning to shift, creating clearer pathways for data-center flexibility
Interconnection policies recognized data center flex/ BYO-VPPs and bundled resources (e.g., Oregon large-load tariffs, Nevada Clean Transition Tariff, SPP’s HILLGA/CHILLGA concepts, CAISO’s interconnection auction). Federal efforts, such as FERC’s large-load interconnection ANOPR and the DOE’s “Speed to Power” initiative, point in the same direction. They provide clear pathways for faster interconnection when large loads bring their own flexible capacity. In addition, they create a set of national policies and rules which will accelerate the adoption of solutions.
Integrated planning and transparent data that ensure data center flex/BYO-VPP capacity is correctly counted for resource adequacy and local constraints. Standards for data access, capacity accreditation, and DER integration help overcome fragmentation and inconsistent performance rules.
Operational and technology services
Revenue optimization services equip data centers with financial management tools that maximize revenue across market segments. They do this while managing operational constraints and risk exposures.
Portfolio balancing services work across facilities for risk management and performance optimization on larger operators that have multiple facilities across utility territories. These tools make it possible to deploy flexibility while managing operational risk across portfolios.
Technology integration services provide vendor-neutral platforms that can coordinate multiple orchestration systems and asset types without requiring single-vendor solutions. This approach eliminates vendors’ locking-in risks while enabling competitive technologies.
Navigating regulations can help provide compliance management for facilities that face complex multi-jurisdictional participation requirements. These services reduce regulatory complexity while ensuring sustained compliance with evolving market rules and performance requirements.
Measurement and Verification (M&V)
Flexibility-contingent interconnection depends on the ability to measure, validate, and, if needed, enforce the flexibility
Clear performance metrics: MWs of load reduction, duration, and timing
Real-time telemetry and automated controls that give utilities reliable visibility into load and flexibility actions.
Credible measurement and verification (M&V) methods, including baselines and settlement logic that both sides trust, and regulators can oversee
Commercial instruments, tariffs or bilateral contracts, that spell out incentives and penalty if commitments are not met
The next chapter
Taken together, these implementation pathways and market mechanisms outline the enabling technologies, business models, and supporting structures that could anchor flexible data-center operations. What remains is aligning market rules and regulatory frameworks to unlock these innovations and establish flexibility as standard operating practice. The next chapter assesses the policy and regulatory shifts required to make this transition durable and scalable.
Schedule of Future Releases
